Blog
Measuring the meaning of “romantic”
The most ambitious corpus so far was collected by Google as part of their book digitalization project (the backbone of Google Books) and covers about 6% of all books ever published. It allows us to give evidence-based answers to many questions of interest to scholars in the humanities, such as the impact of political censorship. I currently use an algorithm for determining a words meaning from its context (known as word2vec) that is based on artificial neural networks (a simulation of neural connections, as in the human brain). By applying this algorithm to books from a specific year it is possible to determine a words meaning in this year. If this is done for multiple subsequent years one can see how a words meaning changed over time, e.g., gay becoming a moniker for homosexuals during the late 20th century.
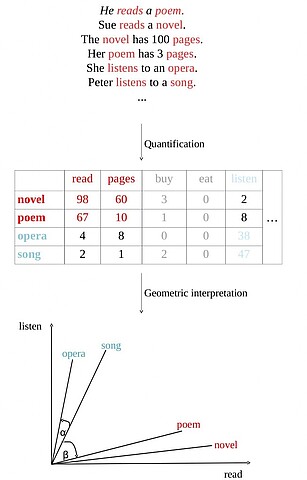
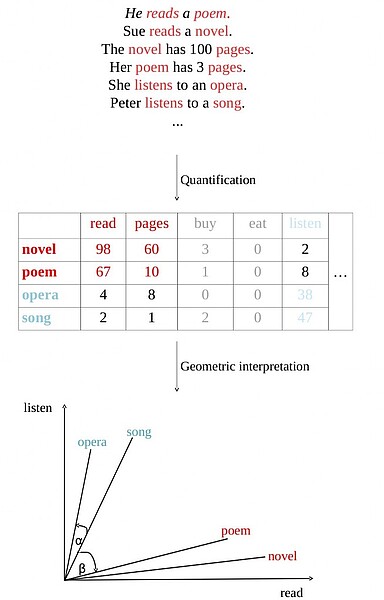
The accompanying graphic shows schematically how the meaning of words can be transformed into a mathematical representation. First a corpus is analyzed, leading to a table listing how often words occurred close to each other, e.g., „novel“ and „read“ co-occurred 98 times in the depicted example. These co-occurrences can be interpreted as coordinates in space, e.g., „song“ occurs far more often with „listen“ than with „read“ and has thus a higher value on the „listen“-axis than on the „read“-axis. The angles between such word representations can be used to quantify the similarity of two words, e.g., the angle between „opera“ and „song“ is small as both have far more in common with each other than „poem“ and „song“, which are separated by a bigger angle.
My research will allow me to quantify the changes “romantic” and other words of importance for romantic literature underwent. As the algorithm is language independent and the corpus covers multiple languages, especially English and German, I will also be able to compare these changes across languages. This will benefit researchers in the humanities by helping them to find interesting changes in meaning, thus guiding their research and making it hopefully more efficient. Analyzing literature via statistics may seem uncommon, yet such approaches (often called distant reading), are frequently explored by researchers working in the digital humanities.
verfasst von Johannes Hellrich